Lets create an empty repository and make one commit.
As we had previously seen, this results in
Lets zoom in and see what happens in a bucket when we commit, merge and rebase.
It is important to understand that a commit corresponds to a whole repository state, not only to files that were included in commit. This would be important later as we experiment with checkout operation: checking out a commit means checking out all files in a repository to a state they were at the time of this commit.
You can think of this as if all your documents in repository are being compacted to a ball every time you make a commit, like on this picture:
Lets introduce a concept of a branch. Branch is just a pointer to a specific commit, nothing more. In git, we always have at least one branch. This default branch is called simply 'master', so, if we zoom in into our bucket, we see:

If we make another commit, the branch pointer is automatically moved to point to our newly created commit
The link between commits A and B means that commit B depends on commit A.
Once again, if we commit even more:
Just because branch is a simple pointer, you can always move this pointer around. This operation is called reset. Here is how reset works:
After this operation you get a repository state as it was at the moment of commit B. We can always return back. It is important to understand that you get all your files to the state they were at the time of commit B, not just files that you actually had in commit B. If you reset back to commit C, you get familiar picture:
One branch is not much fun, so lets create another one. Remember that branch is a simple pointer. We can create branch to point to absolutely any commit in history (including the commit you made three days ago, not just new commits). Lets create a branch that points to commit B.
Notice that bold font marks our current branch, the branch that we actually have checked out on disk. Lets switch to branch 'test'. This operation is called check out.
Lets make some changes and commit them.
And once more:
Oh, we'd like to have our changes from commits D and E in branch 'master'. The are three ways to achieve this: merging, rebasing and cherry-picking.
Lets look at merging. Lets merge our test branch to master.
First, git only supports merging to our current branch, so we need to check out branch 'master':
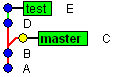 |
| Master is bold: this means active branch |
We already know that in git, commit corresponds to a whole repository state. So as you can guess any merge results in a new commit which corresponds to merged repository state:
 |
| 'F' is a merge commit |
The are two special cases of merge: octopus merge and fast-forward merge. When you merge multiple branches into one branch with a single operation, this is called an octopus merge. It helps to merge for example branches test1, test2 and test3 into master in one operation:
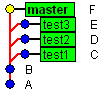 |
| Before octopus merge |
After octopus merge of test1, test2, test3 into master (notice how 'Merge' commit now depends simultaneously on F, E, D, C commits):
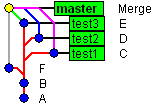 |
| After octopus merge |
Fast-forward merge is not a merge actually as it just helps to get changes from some other branch in case there were no other commits done in our branch since we've branched:
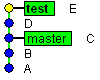 |
| Before fast-forward merge |
The 'master' branch pointer is just moved to point to the same commit branch 'test' points to:
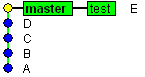 |
| After fast-forward merge |
Rebases are a bit different way to join two branches: it just places all valuable commits from branch test 'over' branch 'master'. Have a look:
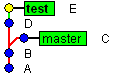 |
| Before rebase |
Notice how E, D commits are now based on commit C. Thats why the operation is called 'rebase': because it just takes interesting commits and changes the commits they were based on:
|
| After rebase |
Cherry-pick is a special case of merge designed to merge a single commit to our current branch. Lets cherry-picking commit D into master. Here is how it looks like:
|
| Before cherry-picking |
Please note, that commit D gets duplicated (is twice in history, this is not an editor error):
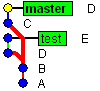 |
| After cherry-picking |
Hope this was an interesting reading.
















